
Prediction Markets Don’t Forecast. They Bet. Here’s Why That Matters.

Robin Hanson wants you to believe that the resistance to prediction markets is about narrative control — that squeamish elites can’t handle uncomfortable truths delivered by the wisdom of crowds. “Markets, they’re not in the control of proper people,” he told Bloomberg recently. “And that’s dangerous.”
It’s a seductive framing. Populist. Anti-establishment. And it completely sidesteps the actual problem.
Prediction markets don’t produce forecasts. They produce bets. And the difference isn’t semantic — it’s mathematical, empirical, and consequential. Conflating the two to expand gambling infrastructure under the banner of epistemic public goods isn’t brave truth-telling. It’s intellectual laundering.
The Math Is Not on Their Side
A bet is a symmetric, one-time commitment. When you buy a “Yes” contract on Kalshi at $0.62, the “No” contract must price at $0.38. They sum to $1.00. They have to — the market mechanism enforces it. This is the Dutch Book theorem, formalized by Bruno de Finetti in 1937: if your prices don’t add up to one, someone can construct a series of trades that guarantee you lose money. Additivity isn’t a feature of prediction markets. It’s a structural constraint.
A forecast is something different. A genuine forecast of the likelihood of an event is time-sensitive, continuously updated as new evidence arrives, and — critically — asymmetric. The probability that something happens and the probability that it doesn’t happen need not sum to one. The gap between them represents real, measurable information: uncertainty, ignorance, or bias in the underlying population.
This isn’t some fringe idea. It’s formalized in Dempster-Shafer theory (1976), where Bel(A) + Bel(¬A) ≤ 1, with the uncommitted belief mass representing what we genuinely don’t know. It’s the foundation of Frank Knight’s distinction between risk and uncertainty (1921). And it’s empirically validated by the Ellsberg Paradox (1961), which demonstrated that real human beings systematically violate additivity when they face ambiguity — because that’s what rational behavior under genuine uncertainty looks like.
Prediction markets take this rich, asymmetric, information-dense reality and crush it into a single number that must obey a constraint the real world doesn’t.
What Gets Destroyed
Consider a Kalshi contract trading at $0.65 on some geopolitical event. What does that number actually tell a decision-maker?
Almost nothing useful.
That $0.65 could mean a deep, well-informed consensus among sophisticated analysts who have converged with high confidence. Or it could mean a handful of traders in a thin market are essentially guessing, with deep disagreement masked by the clearing price. Or it could mean one whale moved the market and nobody has bothered to arbitrage it back.
A genuine forecast framework might tell you: P(event) = 0.65, but P(¬event) = 0.20. The 0.15 gap represents genuine uncertainty — the population doesn’t have enough information to form coherent beliefs on either side. Or it might show P(event) = 0.65 and P(¬event) = 0.34, a nearly additive result suggesting strong evidence has driven convergence. These are radically different information environments that demand different decisions. A prediction market collapses both into the same number.
This isn’t revealing uncomfortable truths. It’s destroying information and calling the residue “insight.”
A Real Example of What This Looks Like
I recently watched this play out in real time on Kalshi’s CPI month-over-month market for June.
Kalshi structures CPI as a set of parallel contracts — “Exactly 0.3%,” “Exactly 0.2%,” “Exactly -0.2%,” and so on. Each contract prices independently. If these were genuine forecasts, the probabilities across all mutually exclusive outcomes should sum to approximately 100%. That’s basic probability theory — the chances of all possible outcomes of a single event must equal one.
At 5:51 AM, they summed to roughly 163%.
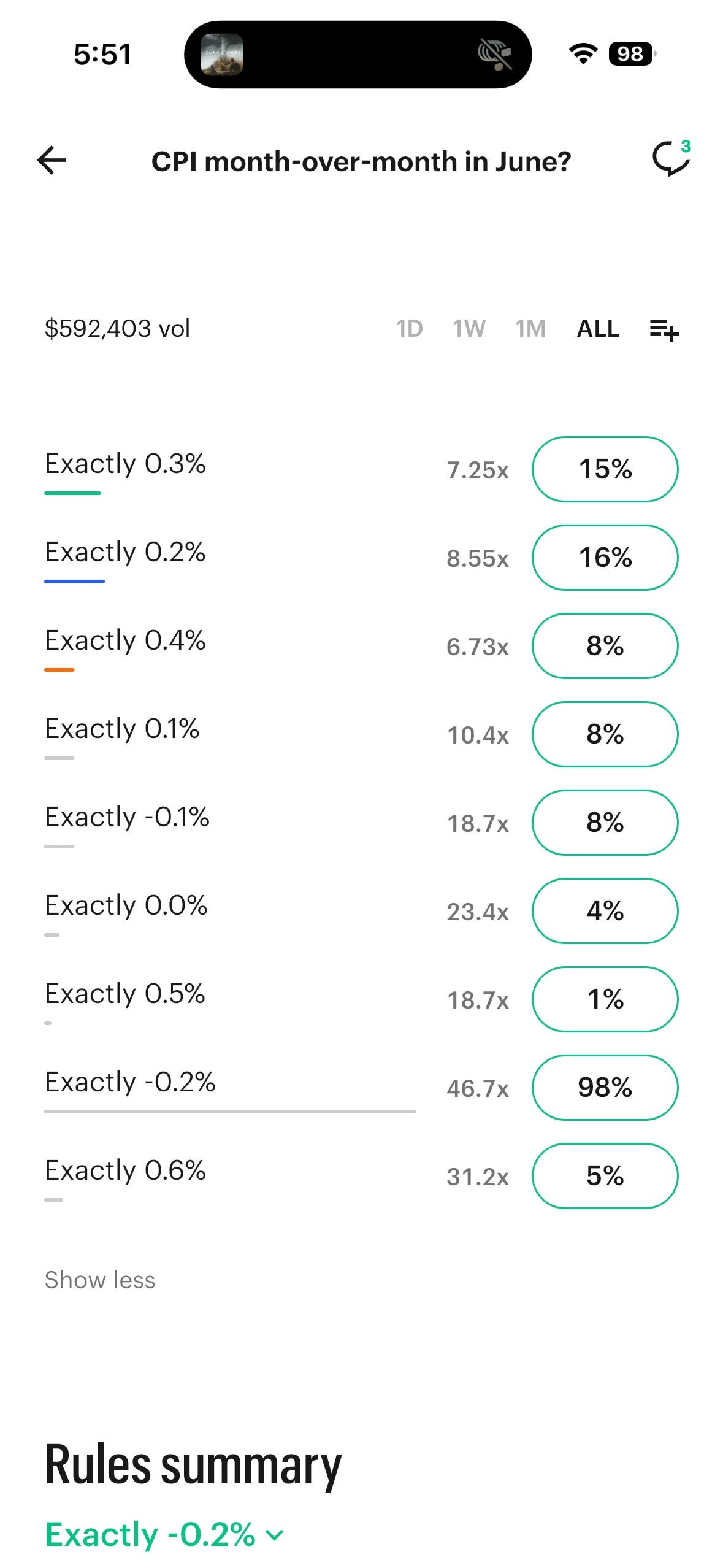
The “Exactly -0.2%” contract alone was priced at 98%, while the remaining contracts collectively summed to another 65%. This isn’t a rounding error. This is a market that is incoherent — it’s assigning more total probability to the set of outcomes than is logically possible. If you took Kalshi’s prices at face value as “forecasts,” you’d be working with a probability distribution that violates the axioms of probability.
But here’s the thing: if you recognize these as bets, the situation makes perfect sense. A set of contracts summing to over 100% is a textbook Dutch Book — the exact scenario de Finetti described in 1937. It means you can buy “No” on every contract simultaneously and guarantee a profit regardless of the outcome, because the overround (the amount exceeding 100%) minus fees is your risk-free return. This is arbitrage, and it’s a concept that belongs entirely to the world of betting, not forecasting.
I attempted to execute exactly that trade. Before I could complete the position across all contracts, Kalshi’s prices shifted. The “Exactly -0.2%” contract collapsed from 98% to 2% in approximately seventeen minutes. The total across all contracts went from 163% to roughly 30% — now under-pricing the probability space, which is equally incoherent in the opposite direction.
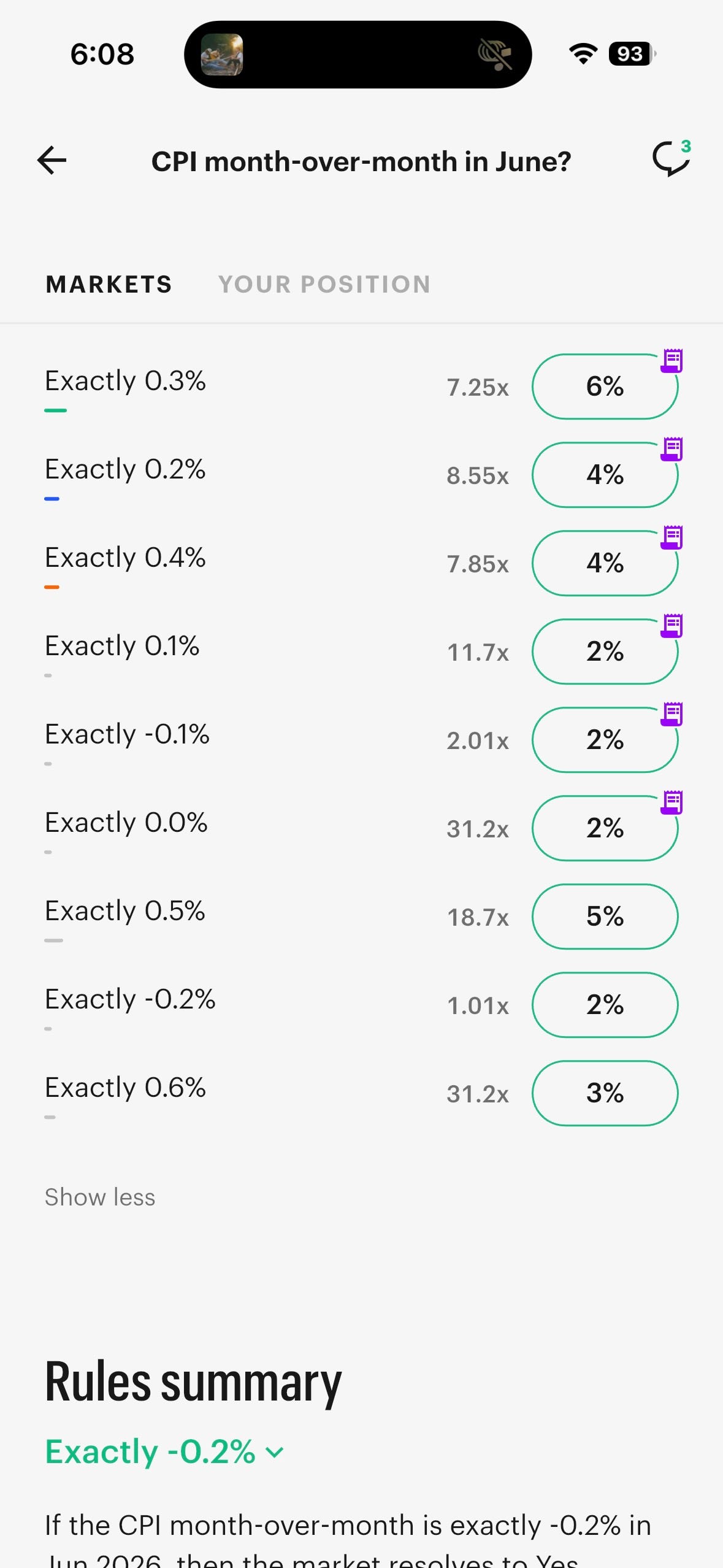
The rapid correction left me holding partial positions that cost money to exit. That’s a normal outcome in betting — you got caught on the wrong side of a price move. But notice what it is not: it is not a “forecast” updating on new evidence. No new CPI data was released in those seventeen minutes. No new economic indicators dropped. What happened was a thin market repriced because the arbitrage opportunity attracted attention. The prices moved because of trading dynamics, not because reality changed.
This is the core problem in miniature. In seventeen minutes, Kalshi’s “forecast” of a single economic indicator swung from a 98% probability of -0.2% CPI to a 2% probability of the same outcome. No forecasting methodology worthy of the name produces a 96-percentage-point revision in the absence of new information. But a betting market with thin liquidity and structural overround? That’s exactly what you’d expect.
If there was an error on the Kalshi platform they should have immediately unwound the contracts and returned funds. They didn’t.
And now you also know the Kalshi secret and where and when to place those “no” bets on the platform for a guaranteed return. 103%+ is the magic number (100% + 2% to cover fees).
The Intellectual Laundering Problem
Watch how Kalshi describes its own platform. When you place a trade, it’s a “bet.” The interface uses betting language. The regulatory framework is betting infrastructure — they fought for and won CFTC approval to operate as an exchange for event contracts, which are, legally and functionally, wagers.
But when they market the platform’s value to the public, to the media, to policymakers? Suddenly the aggregated prices are “forecasts” with democratic significance and epistemic authority.
This is the laundering operation. Bets go in, “forecasts” come out. The transformation is purely rhetorical. The underlying mechanism hasn’t changed. The additivity constraint is still there. The information loss is still there. But “forecast” sounds like something a policymaker should consult, while “bet” sounds like something a regulator should scrutinize.
Hanson’s framing assists this operation brilliantly. By casting the debate as brave-markets-vs-cowardly-elites, he deflects attention from the epistemological question entirely. You’re not allowed to ask “does this mechanism actually produce calibrated, uncertainty-aware probability estimates?” because that question has been preemptively reframed as elite discomfort with inconvenient truths.
The Thermometer That Only Reads in Whole Degrees
Here’s an analogy. Imagine a thermometer that rounds every reading to the nearest ten degrees. It reads 70°F. Is the room 65°F or 74°F? You don’t know. The instrument has destroyed that information by design.
Now imagine someone markets this thermometer as a “precision climate instrument” and argues that anyone who questions its readings is afraid of uncomfortable temperatures.
That’s prediction markets. The Dutch Book constraint is the rounding function. It takes continuously valued, asymmetric, uncertainty-rich information about what populations actually believe and forces it through a mechanism that outputs a single additive number. Then it presents that number as if it were the underlying reality rather than a lossy compression of it.
A real forecasting methodology preserves the asymmetry. It measures P(A) and P(¬A) independently, lets the gap speak for itself, and tracks how both estimates evolve over time. The pattern of movement — whether shifts are symmetric (suggesting genuine new evidence) or asymmetric (suggesting manipulation or information operations) — is itself a critical signal.
Prediction markets can’t detect that signal. It’s been engineered out of the system.
The Population Problem
There’s a second, less discussed issue. Prediction markets don’t measure population beliefs. They measure the revealed preferences of people willing to wager money on events, which is a narrow, systematically unrepresentative slice of any population.
The people who trade on Kalshi and Polymarket skew young, male, financially sophisticated, risk-tolerant, and politically engaged in specific ways. Their collective price reflects their consensus, not the beliefs of the populations whose behavior decision-makers actually need to understand.
When the Department of Defense needs to know what a population in a contested information environment believes about their government’s legitimacy, a prediction market price from crypto-native traders in New York is not just unhelpful — it’s misleading. When a corporation needs to understand how consumer beliefs are shifting about product safety or brand trust, the revealed preferences of financial speculators are a non-sequitur.
Hanson’s “uncomfortable truths” argument implicitly assumes that the truth being revealed is representative. But a market dominated by a non-representative population produces a precise estimate of the wrong thing.
What Hanson Gets Right, and What He Misses
Hanson is correct that institutions resist information mechanisms they can’t control. That’s real. Legacy media, government agencies, and corporate leadership all have incentive structures that sometimes conflict with accurate probability estimation.
But his conclusion — that prediction markets are the solution — doesn’t follow. The fact that existing institutions are imperfect at forecasting doesn’t mean a betting exchange is better. It might be worse in a more precise way: confidently wrong instead of vaguely right.
The real solution isn’t to replace narrative-controlled estimates with structurally impoverished ones. It’s to build forecasting methodologies that preserve uncertainty information, measure actual populations, update dynamically, and resist manipulation — not by making manipulation expensive (the prediction market approach), but by making it detectable.
The Stakes
This isn’t an academic debate. The expansion of prediction markets into elections, geopolitics, public health, and corporate decision-making has real consequences. If policymakers begin treating Kalshi prices as forecasts — as calibrated, uncertainty-aware probability estimates — they will make worse decisions. They’ll miss the information that lives in the gap between P(A) and P(¬A). They’ll be blind to asymmetric manipulation. And they’ll do it with false confidence, because the number on the screen looks so precise.
Calling a bet a forecast doesn’t make it one. It makes it a bet with better marketing. And building a society’s decision-making infrastructure on that conflation isn’t democratizing truth. It’s industrializing a category error.
-J